- 논문 제목: HoloCine: Holistic Generation of Cinematic Multi-Shot Long Video Narratives
- 발표/수정일: 2025-10-23
- 저자: Yihao Meng, Hao Ouyang, Yue Yu, Qiuyu Wang, Wen Wang, Ka Leong Cheng, Hanlin Wang, Yixuan Li, Cheng Chen, Yanhong Zeng, Yujun Shen, Huamin Qu
- 소속: HKUST, Ant Group, ZJU, CUHK, NTU
- 연구 분야: Text-to-Video Generation, Multi-shot Cinematic Synthesis, Diffusion Transformer
- 키워드: multi-shot video, narrative coherence, window cross-attention, sparse inter-shot attention, cinematic controllability
- 출처: arXiv
- 논문 URL: https://arxiv.org/abs/2510.20822
- 코드 URL: https://holo-cine.github.io/
🧠 연구 배경 및 문제 정의
영화, 드라마, 광고는 촬영 감독의 의도를 담은 다중 샷 구성으로 서사 흐름을 만든다. 그러나 확산 기반 T2V 모델은 여전히 단일 샷, 짧은 클립에 최적화돼 있어 다음과 같은 한계를 보였다.
- 샷 단위 통제 실패: 프롬프트에 명시된 샷 길이, 전환 지점을 해석하지 못해 단일 롱테이크로 응답.
- 인물·배경의 불일치: 복수 샷 생성 시 등장인물의 외형, 배경 오브젝트가 달라지는 현상.
- 계산 비용의 폭증: 단일 시퀀스 전체에 완전 연결(Self-Attention)을 적용하면 길이에 따라 메모리가 제곱으로 증가.
이에 저자들은 “텍스트 프롬프트 → 샷 별 서술 → 장면 전체”로 이어지는 계층형 프롬프트 구조를 이해하고, 동일 인물·배경을 유지하면서도 샷 전환을 유연하게 제어하는 모델이 필요하다고 판단했다. 동시에, 초당 수백 토큰이 포함되는 비디오 시퀀스를 처리하면서도 훈련·추론 비용을 억제하는 메커니즘이 요구된다.
📊 실험 및 결과 (Experiments & Results)
정량 평가
- 벤치마크 구성: Gemini 2.5 Pro를 이용해 생성한 100개의 계층형 프롬프트 세트. 각 프롬프트는 샷 전환, 카메라 무브, 등장인물 정보를 포함.
- 평가지표:
- Shot Cut Accuracy(SCA)로 전환 지점의 개수·타이밍 정확도를 측정.
- VBench 기반 점수로 의미 일치, 주체/배경 품질, 미학적 품질, 샷 내 일관성 평가.
- ViCLIP 유사도로 샷 간 동일 인물의 일관성을 정량화.
- 성능: HoloCine은 SCA 0.9837, Inter-shot Consistency 0.7509, Intra-shot Consistency 0.9448, Semantic Consistency 0.9352를 달성. Aesthetic Quality 0.5598도 StoryDiffusion+Wan2.2(0.5773)에 근접.
- 베이스라인 비교: Wan2.2 14B 단독, StoryDiffusion+Wan2.2, IC-LoRA+Wan2.2, CineTrans 대비 전 범주에서 우위. 특히 SCA에서 두 배 이상 차이로 샷 경계 해석 능력을 입증.
정성 평가
- 동일 프롬프트에서 Wan2.2는 단일 샷만 생성, StoryDiffusion/IC-LoRA는 인물 외형이 샷마다 달라짐.
- CineTrans는 장면 길이가 길어지며 해상도가 붕괴. 반면 HoloCine은 샷별 지시(“여성의 근접 클로즈업” 등)를 정확히 반영해 완성도 높은 5샷 시퀀스를 생성.
- 상용 모델(Vidu, Kling 2.5 Turbo)과 비교해도 HoloCine만이 다중 샷을 이해. Sora 2와 유사한 샷 전환 제어력을 시연.
어블레이션
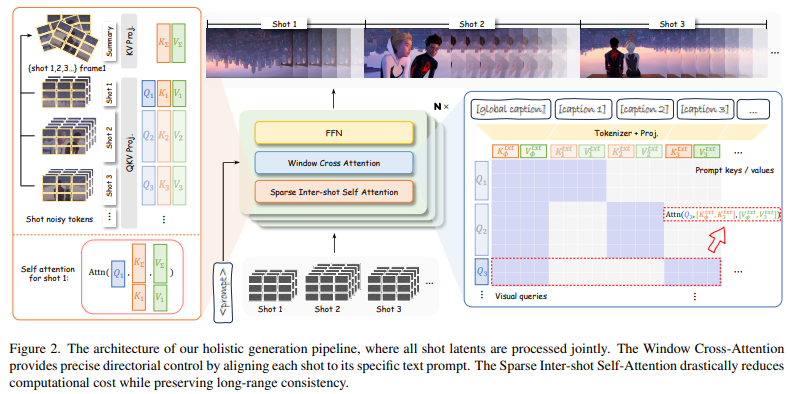
- Window Cross-Attention 제거: SCA 급감(0.6266) 및 샷 전환 실패.
- Dense Self-Attention: 품질은 양호하지만 메모리 사용량이 치솟아 실용성이 떨어짐.
- Summary Token 제거: 인물 일관성 붕괴, 캐릭터 외형이 샷마다 변형.
- Sparse 설정: 5B 모델에서도 SCA 0.9736, Inter-shot 0.7225로 최적 균형 확보.
고급 능력 및 한계
- Emergent Memory: 장면 전반에 등장하는 소품·인물 외형을 기억해 샷 1과 샷 n 사이에서도 일관성을 유지.
- Cinematic Controllability: 샷 스케일(롱·미디엄·클로즈업), 카메라 앵글(로우·아이레벨·하이), 카메라 무브(틸트 업, 돌리 아웃, 트래킹)를 정확히 재현.
- 한계: 물리·인과 추론이 부족해 물을 따르는 장면 이후 컵이 여전히 비어 있는 등 상태 변화를 반영하지 못함. 이는 시각적 일관성에 치중한 결과로, 향후 동적 물리 모델링이나 후속 시뮬레이션과의 결합이 요구된다.
🔖 참고 자료 (Reference Info)
- Meng, Y., Ouyang, H., Yu, Y., Wang, Q., Wang, W., Cheng, K. L., Wang, H., Li, Y., Chen, C., Zeng, Y., Shen, Y., & Qu, H. (2025). HoloCine: Holistic Generation of Cinematic Multi-Shot Long Video Narratives. arXiv:2510.20822.
- Ma, Z., Guo, Y., Yang, C., Jiang, L., & others. (2025). Mixture of Contexts for Long Video Generation. arXiv:2508.21058.
- Bansal, H., Bitton, Y., Yarom, M., et al. (2024). TALC: Time-Aligned Captions for Multi-Scene Text-to-Video Generation. arXiv:2405.04682.
📝 리뷰어 노트 (Reviewer’s Note)
HoloCine은 샷 제어와 일관성을 실질적으로 해결했지만, 인과 추론 부족이 장면의 논리성을 해칠 수 있다. 긴 시퀀스를 처리해도 그래픽 품질이 안정적이어서 프로덕션 퀄리티에 근접하며, 공개된 구현이 연구 커뮤니티의 재현성 확보에 기여한다. 후속 연구에서는 물리 기반 파인튜닝이나 외부 시뮬레이터와의 결합으로 서사의 논리적 정합성을 강화할 필요가 있다.